双宽带上传叠加,实现异地 4K 串流
我玩异地串流已经很多年了。从读研时期起,我配了我的第一台台式机。之后每年寒暑假回家我都会不断优化我的串流体验。异地串流就像魔法一样,让我可以在家里巨大的电视屏幕上运行画面精美的大型游戏,或者连上键盘鼠标后化作一个云电脑,而这一切只需要插上一条网线。
在直线距离 322km 的异地(网络延迟在 20ms 左右),我串流玩过像素风的ARPG 游戏神之天平、玩过画面精美的 3A 大作、玩过本地多人的游戏双人成行、玩过需要考验操作的动作游戏怪物猎人,还串流过 VR 游戏半条命:艾利克斯、恐怖游戏森林。我的所有串流经历里挑战最高的是串流 VR 游戏,VR 画面需要非常高的带宽,并且对延迟非常敏感,高延迟很容易造成眩晕感。串流 VR 大致需要 80Mbps 带宽,并且总延迟需要低于 45/60ms。
然而我以往的串流体验依赖于学校提供的完美网络条件——有着千兆对等的宽带,还能选择三网出口来降低延迟。在我毕业后,我办理的移动千兆宽带只有 40Mbps 的上传带宽。这使得我回家后再也无法串流 VR 游戏,并且也只能 1080p 串流 PC 游戏,这显然是一个巨大的打击。
学校的网络通服务每个月20元,提供了千兆对等的带宽、CERNET 的 v4 公网 IP 和 /60 的 v6 公网 IP。并且除教育网外,还支持切换到三大运营商的出口(NAT)。利用这完美的资源,我把我的台式机打造成了一台高性能的云游戏服务器,利用 wireguard 组网,实现了在家里访问学校的台式机。
我询问了线下三大运营商的门店,但貌似都不太懂,都说没有更高上传的普通宽带。联通提供的便宜专线 300/100Mbps 需要 120 元/月,仍然太贵。之前听朋友说福建移动有 50 元上传提速到 300Mbps 的服务,但是我问了给我装宽带的移动师傅,并不知道这种事情。
我之前给朋友办了一条千兆宽带(二宽优惠,10 元千兆)。在 25 年 12 月份,朋友说宽带 1 月底就不用了。那时我便萌生了之后将其移机,聚合两条宽带的想法。
最终,这个想法在 1 月 24 号被正式实施。利用 ipv6 没有 uRPF 的特性,通过 wireguard 组网,并使用 nft 实现 UDP 包 per-packet 的负载均衡,最后成功把两条移动宽带的上行叠加在一起。
这次过年回家,我实际测试了 4K 串流的游戏体验,并使用 SQM 优化了带宽叠加的稳定性。最终实现了低于20ms延迟、4K@60fps HDR、70 Mbps 码率的稳定串流的效果。遂写此文记录折腾心得,希望能帮助同样喜欢异地串流的同好。
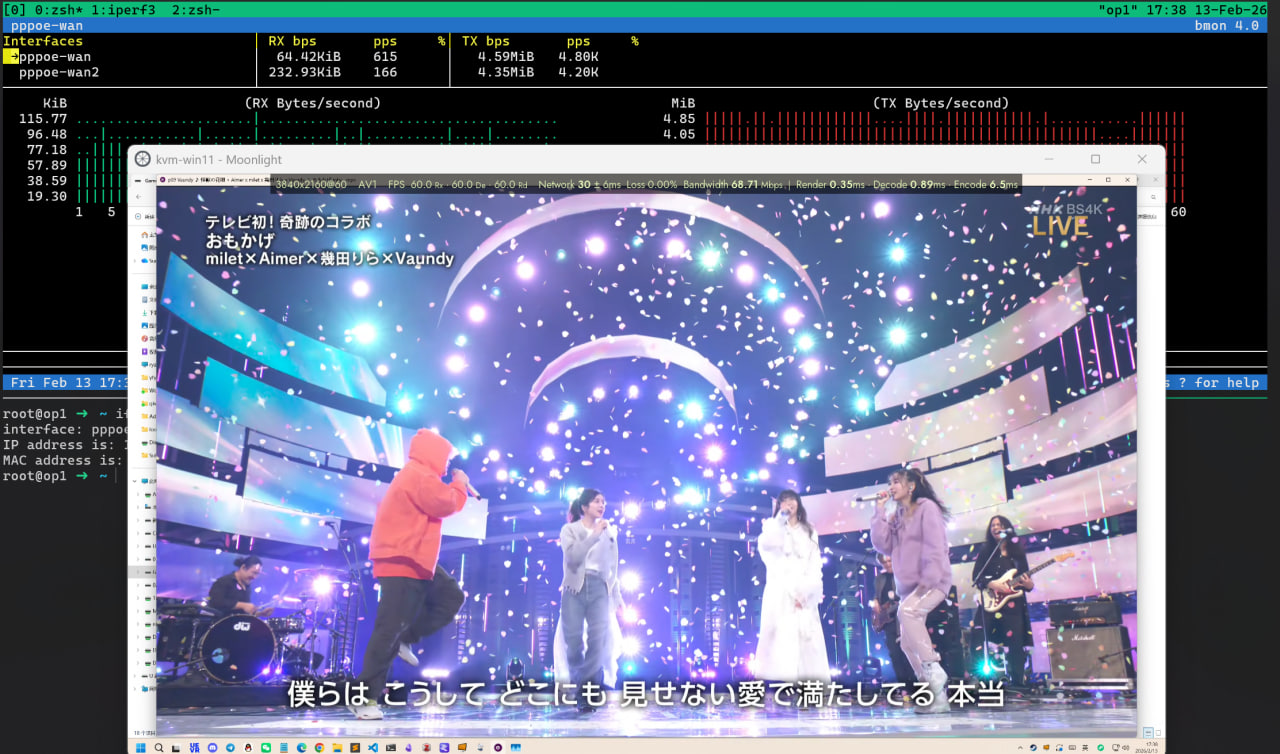
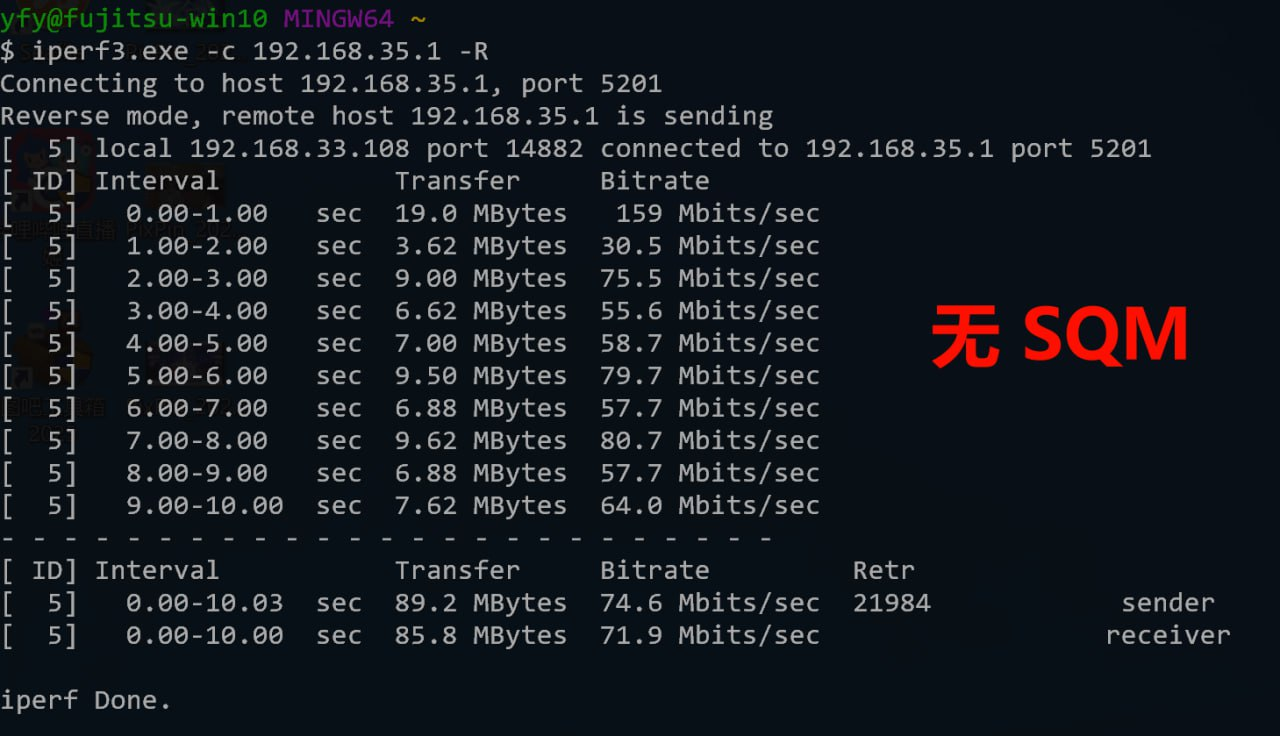
图1:串流跑到 68 Mbps 码率,不丢包(SQM 优化前)
大纲
- 宽带移机风波
- 与宽带师傅的掰扯
- 一波三折的安装
- 软路由双 wan 设置
- wireguard 带宽叠加配置
- ipv6 uRPF 测试
- 基于 nft 的 UDP Per-Packet 负载均衡
- iperf3 测试
- 过年回家串流测试
- 失效的排查
- SQM 优化
- 结语
宽带移机风波¶
由于是在要一户内拉两条同一个运营商的宽带,比较少见,因此没那么顺利。为了将宽带移机过来,最后的方案是使用一个 1 分 2 分光器,将入户光纤分成两个,接在两个光猫上(注意,分光器的输入光纤也是公口,因此需要一个法兰盘(耦合器)与入户光纤对接)。光功率从 -16.8 dbm 降低为一个 -20 dbm,一个 -23 dbm,均位于 -24 的正常范围内。
PON 基础知识¶
在刚开始和宽带师傅 A 沟通移机的过程中,由于不懂光纤入户方面的知识,所以显得很被动,只能听师傅讲什么是什么。然后结论就是让我拉线,收费 400。在请教群友后,才了解到分光器等知识,于是去了解了下现代宽带光纤入户的原理。
分享一篇有关光纤入户折腾的博客,由此了解了很多 PON 基础知识。波分单线复用笑传之Custom Combo Broadband - 蚊帐
Gemini 总结:
PON (Passive Optical Network,无源光网络) 是现代光纤入户的核心架构
- 自来水厂 (OLT - 机房端):
- 这是源头。一根粗光纤从机房出来,携带了成千上万户人家的数据。
- 特点: 不同运营商(移动、电信)通常有各自的“水厂”和管道。所以群友说“同运营商可以用分光器,不同运营商不行”。
- 主管道与阀门 (ODN - 光分配网):
- 光纤从机房出来,经过路边的交接箱,再到小区的机房,最后到你楼道的弱电井。
- 在这个过程中,光信号经过了层层分光器。
- 比如:机房出来 1 分 4,到了小区再 1 分 16,最后到楼道可能是 1 分 64。
- 关键点: 这中间的所有设备都不需要插电(所以叫“无源”),完全靠物理光学的折射/反射。
- 水龙头 (ONU - 光猫端):
- 这就是你家。
为什么你家可以用分光器?
因为 PON 网络本质上就是一根光纤共享给几十个用户。
- 下行(下载): 它是广播模式。机房就像大喇叭,把所有人的数据(张三看电影、李四打游戏)都发到这根光纤上。你家的光猫虽然接收到了所有数据,但它只筛选出“写着你名字”的数据包,扔掉别人的。
- 上行(上传): 它是时分复用 (TDMA) 模式。因为大家共用一根线,不能同时说话(否则光会冲突)。光猫会听从机房指挥:“现在轮到张三发数据,李四闭嘴”,大家排队快速发光。
总结:
你在家里加一个分光器,在物理层面上,只是相当于把运营商原本的 1:64 分光,人为变成了 1:65(或更细微的分支)。只要光信号强度足够让光猫识别出 0 和 1,对于机房的设备来说,它根本不知道(也不在乎)这根光纤是在楼道分的,还是在你家客厅分的。它只认光猫的注册码 (LOID/SN)。
与宽带师傅的掰扯¶
刚开始说移机,师傅说移不了。为此掰扯了很久,他们发的消息有的有错别字,或者用的术语没听过,让人摸不着头脑。总结下来他们说的有用信息
- 我们这入户是一路光纤(还有单独一路广电)
- 楼道光配箱可能是 64 口,只给每户留了 1 个口,所以刚开始和我说没办法装两条宽带
- -25 dBm 是弱光,会被罚钱
- 我现在的可能是接在 32 分光器上,如果之后用 64 分光器,光功率可能就不够了(装完后说的)
在刚开始计划移机时,我联系了给我装宽带的师傅 A,他说我这小区入户只有一路光纤,装不了。我说加钱行吗,他说拉线要 400,移机可以不收费。 之后我在网上咨询了群友,了解到可以在户内使用 1 分 2 分光器。于是再次联系了 A,但是 A 和我说带不动,说会掉 10 个点。最后他说他现在不负责我那片小区了,让我联系宽带师傅 B。
在和 B 说了我的方案后,B 也认定没有 1 分 2 分光器,然后也说没办法拉线(原话是说户线穿不过去,强行穿线可能把原本光纤弄断)。我提供了淘宝分光器和我的光猫 -16.8dbm 的光功率截图,并说这个和 FTTR 业务原理应该一样吧。他说和 FTTR 不一样,FTTR 是主光猫发送光信号给子光猫。还说一个 “庞口” 64户,多一个都不行,加不上去。不过最后还是说可以给我试一下,并说我很专业。
由于不懂师傅说的 “庞口” 是什么,还有所谓 64 口的限制,所以师傅的话还是没搞懂。不过我感觉应该是没啥问题的。最后,和师傅约定好周六来装,由我准备好分光器(到货后发现忘记买耦合器了,怕来不及让师傅带了几个耦合器)。师傅还说来过年时候不忙没啥事,忙的话就不会来了,还说不要上门费(不过当天让我在移动 APP 申请时还是支付了 100 元,我觉得还算正常,因此也没过问)
关于物料购买
- 1分2 分光器(SC-UPC,蓝色方头):
- 光纤耦合器/法兰盘
- (不需要,分光器自带线)两根短光纤跳线(冷接头/成品线):用于连接分光器和两个光猫。

一波三折的安装¶
超密无效
宽带师傅比预定的 9 点提前半小时到了,使用一个带屏幕的便携设备连接到了光猫上准备移机,不过试了几次查询到的光猫密码,都提示错误。他接着打了电话询问了别人,不过也没有得到解决办法。最后只好说下次再来,给我换一个光猫。好在中午我从朋友那问到了正确的密码,师傅同意再过来给我装。
后面从群友那学到的光猫忘记超密后的处理方法
- 记录 LOID 等信息
- 重置光猫
- 光猫后面贴纸上的密码是普通用户,无法用于注册,因此要想办法获得超密
- 重置后移动光猫超密默认是通用超密:
aDm8H%MdA
宽带密码无效
在测试了光衰都没问题后,我将光猫改成了桥接,然后使用路由器拨号上网(使用之前记录的密码),结果怎么都拨号不成功。我想把宽带密码重置,结果移动 APP 最后一步无法提交成功。到最后突然发现手机上收到了移动的短信,说检测到我的移机申请,自动给我的宽带密码重置成了全 0 (这也太坑了)。于是输入正确密码后终于拨号成功了。
小插曲:宽带师傅不知道如何让超密保持不变,我给他说明了通过删除 tr069 的连接,来禁止 ISP 下发配置,可以避免超密被修改。
最终光功率对比
宽带 A 的光猫
- 支持启用 wifi6 热点
- GPON
- -16.6dbm -> -20
宽带 B 的光猫
- 没有 wifi
- XGPON
- ? -> -23.2
XGPON 的光猫光功率要低 3 个点,可能是光波长的原因。
软路由双 wan 设置¶
- 本来希望使用 vlan 技术,把软路由 4 个网口使用一个 vlan awareness bridge 管理起来
- 软路由 vlan 设置如下表,5 是 wan1,6 是 wan2,10 是 lan
- 好处是:现在使用 2 个物理网口作为 wan,必要时可以仅使用 1 个网口连接在交换机上,然后使用 vlan 进行端口复用(我有一个 8 口 2.5G 交换机,端口用不完)
- 但是发现在我设置了 vlan 后,wan1 pppoe 就是拨号不成功,即使对应端口 5 已经是 untagged 和 pvid。
- 最后只好使用基本方案,创建两个普通的 bridge(vmbr0 和 vmbr10),软路由虚拟机连接到这两个 bridge 上
| 说明 | enp5s0 | enp4s0 | enp3s0 | enp2s0 | |
|---|---|---|---|---|---|
| 5 | wan1 | u* | |||
| 6 | wan2 | u* | |||
| 10 | lan | u* | u* | ||
| 20 | lan2 | t | t |
wireguard 带宽叠加配置¶
本节实现了两条带宽上传的叠加,将 wg 隧道的单向带宽从 40mbps 提升到了 70mbps。
ipv6 uRPF 测试¶
本节的方案依赖于 ipv6 源地址欺骗技术,这需要 ISP 没有开启 uRPF。uRPF 相关概念参考链接:
- Unicast Reverse Path Forwarding (uRPF)
- uRPF 在互联网服务提供商网络中有意义吗? « ipSpace.net 博客 --- Does uRPF Make Sense in Internet Service Provider Networks? « ipSpace.net blog
好在 ipv6 一般是没有开启的。为了测试,我们需要将源地址是 wan1 v6 ip 的包,从 wan2 接口上发送出去,并测试是否可以正常访问互联网。
刚开始尝试了以下几种方法,没办法进行测试
ping -I ip- -I 没办法既指定接口,又指定源 ip,只能选其一
- openwrt
-I选项需要安装完整版 ping:iputils-ping
traceroute -i iface -s ip- traceroute 会遇到 bind 失败问题
root@op1 ➜ ~ traceroute -6 -i pppoe-wan -s 2409:8a30:40a:949c::A 2400:3200::1
traceroute to 2400:3200::1 (2400:3200::1) from 2409:8a30:40a:949c::A, 30 hops max, 72 byte packets
1 2409:8030:1:1::205 (2409:8030:1:1::205) 3.902 ms 7.962 ms 3.850 ms
2^C
root@op1 ➜ ~ traceroute -6 -i pppoe-wan -s 2409:8a30:40a:94b0::B 2400:3200::1
traceroute to 2400:3200::1 (2400:3200::1) from 2409:8a30:40a:94b0::B, 30 hops max, 72 byte packets
1traceroute: sendto: Network unreachable
最后使用策略路由方法测试成功:
# 1. 增加一条路由:在表 200 中,设置默认网关为 pppoe-wan2
# **PPPoE 是点对点连接,不需要指定 via 网关 IP,直接指定 dev 即可**
ip -6 route add default dev pppoe-wan2 table 200
# 2. 增加一条策略规则:所有源 IP 是 WAN1 IP 且目的是阿里云 v6 dns 的包,强制去查表 200
ip -6 rule add from 2409:8a30:40a:94b0::A to 2400:3200::1 table 200 prior 5
# 3. 刷新路由缓存(让规则立即生效)
ip -6 route flush cache
使用 ping 测试,src 指定 wan1 ip
tcpdump 结果显示,包从 wan2 出去,从 wan1 返回。这说明 ISP ipv6 没有启用 uRPF
root@op1 ➜ ~ tcpdump -i any icmp6 and host 2400:3200::1
tcpdump: WARNING: any: That device doesn't support promiscuous mode
(Promiscuous mode not supported on the "any" device)
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on any, link-type LINUX_SLL2 (Linux cooked v2), snapshot length 262144 bytes
16:11:01.735326 pppoe-wan2 Out IP6 2409:8a30:40a:b38c::A > 2400:3200::1: ICMP6, echo request, id 33413, seq 1, length 64
16:11:01.758877 pppoe-wan In IP6 2400:3200::1 > 2409:8a30:40a:b38c::A: ICMP6, echo reply, id 33413, seq 1, length 64
基于 nft 的 UDP Per-Packet 负载均衡¶
要实现带宽叠加有很多方法。其中 ECMP 是一个常见的技术,我以前也尝试过。但是该技术目前只能做到 per-flow 的负载均衡。这意味着单连接场景仍然无法叠加带宽。并且多连接场景,也很容易遇到流量都走到一个接口的情况。
在询问 gemini 时,gemini 提供了一个使用 nft 和 策略路由实现 UDP Per-Packet 的负载均衡方案。由于是对每个 UDP 包处理,因此能够实现流量在两个 wan 口上均匀的分配。
以下配置针对 openwrt。
nftables 设置¶
目标:使用 nft 将所有 ipv6 udp 包轮流打上 0x100 和 0x200 的 mark,触发重路由
添加 nft 文件 /etc/nftables.d/12-wg_spoof.nft ,内容解释:
- 在 output 链上添加规则,只对路由器发出的流量生效,如果需要对转发流量也生效,需要使用 prerouting 表
- type 需要为
route,否则不会触发重路由 - 使用
ip6 nexthdr udp限制只对 UDP 包生效,对于 wireguard 来说够了
#/etc/nftables.d/12-wg_spoof.nft
# 链:处理路由器本机发出的流量
chain wg_spoof_output {
type route hook output priority mangle; policy accept;
ip6 nexthdr udp mark set numgen inc mod 2 map { 0 : 0x100, 1 : 0x200 } counter
}
# 如果以后需要处理转发流量
# chain wg_spoof_prerouting {
# type route hook prerouting priority mangle; policy accept;
# }
策略路由设置¶
目标:使用策略路由,将打上标签的包路由到对应出口
vim /etc/iproute2/rt_tables增加 wan 和 wan2 两个表- 设置 ipv6 的策略路由和路由规则
config route6
option interface 'wan'
option target '::/0'
option table 'wan'
config route6
option interface 'wan2'
option target '::/0'
option table 'wan2'
config rule6
option priority '9'
option lookup 'wan'
option mark '0x100'
config rule6
option priority '9'
option lookup 'wan2'
option mark '0x200'
最后效果
root@op1 ➜ ~ ip -6 ru
0: from all lookup local
9: from all fwmark 0x100 lookup wan
9: from all fwmark 0x200 lookup wan2
32766: from all lookup main
root@op1 ➜ ~ ip -6 route show table wan
default dev pppoe-wan metric 1024 pref medium
root@op1 ➜ ~ ip -6 route show table wan2
default dev pppoe-wan2 proto static metric 200 pref medium
效果测试¶
iperf3 测试在 70Mbps
root@op3 ➜ ~ iperf3 -c 10.0.32.1 -R
Connecting to host 10.0.32.1, port 5201
Reverse mode, remote host 10.0.32.1 is sending
[ 5] local 10.0.32.3 port 58138 connected to 10.0.32.1 port 5201
[ ID] Interval Transfer Bitrate
[ 5] 0.00-1.00 sec 20.8 MBytes 174 Mbits/sec
[ 5] 1.00-2.00 sec 8.88 MBytes 74.4 Mbits/sec
[ 5] 2.00-3.00 sec 8.12 MBytes 68.2 Mbits/sec
[ 5] 3.00-4.00 sec 8.88 MBytes 74.4 Mbits/sec
[ 5] 4.00-5.00 sec 8.38 MBytes 70.3 Mbits/sec
[ 5] 5.00-6.00 sec 8.88 MBytes 74.4 Mbits/sec
[ 5] 6.00-7.00 sec 8.75 MBytes 73.4 Mbits/sec
[ 5] 7.00-8.00 sec 8.38 MBytes 70.3 Mbits/sec
[ 5] 8.00-9.00 sec 8.62 MBytes 72.4 Mbits/sec
[ 5] 9.00-10.00 sec 8.50 MBytes 71.3 Mbits/sec
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-10.02 sec 101 MBytes 84.4 Mbits/sec 8228 sender
[ 5] 0.00-10.00 sec 98.1 MBytes 82.3 Mbits/sec receiver
SMB 复制文件跑到 9.25MB/s
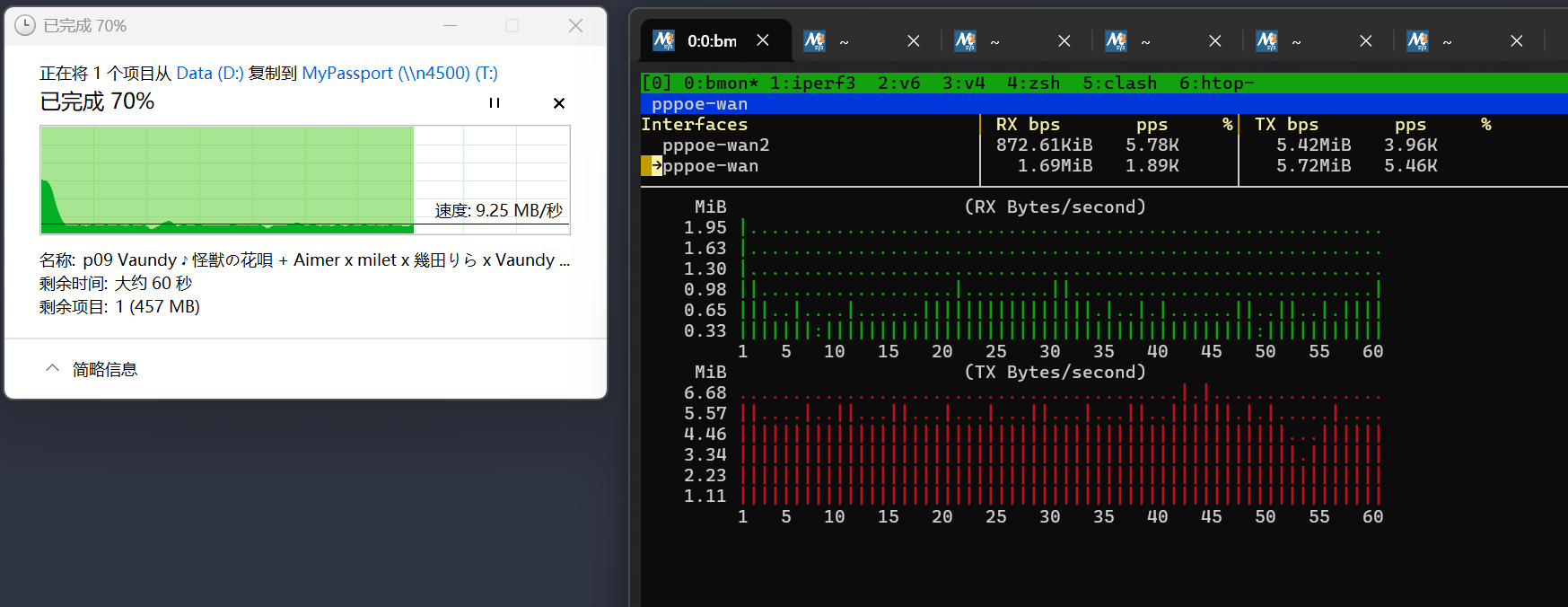
过年回家4K串流测试¶
失效的排查¶
过年回来后,最期待的就是测试一下串流的效果。但是没想到回来第一天晚上测试,发现带宽叠加失效了,nft trace 调试了很久也没找到问题。此时透明代理也失效了,tg 登不上去。网络的两个问题让我心理始终不得劲,但是又没办法快速修好,所以也无可奈何。第二天出去吃酒了,没多少时间测试。直到第三天早上,我终于静下心来,开始排查网络的问题。透明代理的问题被发现是防火墙的问题导致的,添加一条允许转发规则后,问题便解决了。第一个问题的解决让我信心大增,开始排查我最关心的带宽叠加问题。
我之前用 nft trace 调试功能已经发现 nft 规则是生效了的,wireguard 的 udp 包被轮流打上了不同 mark,问题在于后续没有触发重路由。为了更容易分析,我专门构造了一条 nft 规则,将目的地址是阿里云 dns 的所有 ipv6 包打上 0x200 mark(wan2),结果仍然是没有触发重路由,最终还是从 wan1 出去了。nft trace 结果如下:
trace id a7268f01 inet fw4 trace_chain packet: oif "pppoe-wan" ip6 saddr 2409:8a30:40a:b38c::A ip6 daddr 2400:3200::1 ip6 dscp cs0 ip6 ecn not-ect ip6 hoplimit 64 ip6 flowlabel 175028 ip6 nexthdr ipv6-icmp ip6 length 64 icmpv6 type echo-request icmpv6 code 0 icmpv6 parameter-problem 2497511425 icmpv6 taddr 0:0:618d:8d69::3b8b:a00
trace id a7268f01 inet fw4 trace_chain rule ip6 daddr 2400:3200::1 meta nftrace set 1 counter packets 0 bytes 0 (verdict continue)
trace id a7268f01 inet fw4 trace_chain verdict continue
trace id a7268f01 inet fw4 trace_chain policy accept
trace id a7268f01 inet fw4 wg_spoof_output packet: oif "pppoe-wan" ip6 saddr 2409:8a30:40a:b38c::A ip6 daddr 2400:3200::1 ip6 dscp cs0 ip6 ecn not-ect ip6 hoplimit 64 ip6 flowlabel 175028 ip6 nexthdr ipv6-icmp ip6 length 64 icmpv6 type echo-request icmpv6 code 0 icmpv6 parameter-problem 2497511425 icmpv6 taddr 0:0:618d:8d69::3b8b:a00
trace id a7268f01 inet fw4 wg_spoof_output rule ip6 daddr 2400:3200::1 icmpv6 type echo-request meta mark set 0x00000200 counter packets 3 bytes 312 (verdict continue)
trace id a7268f01 inet fw4 wg_spoof_output verdict continue meta mark 0x00000200
trace id a7268f01 inet fw4 wg_spoof_output policy accept meta mark 0x00000200
trace id a7268f01 inet fw4 oversea_mangle_output packet: oif "pppoe-wan" ip6 saddr 2409:8a30:40a:b38c::A ip6 daddr 2400:3200::1 ip6 dscp cs0 ip6 ecn not-ect ip6 hoplimit 64 ip6 flowlabel 175028 ip6 nexthdr ipv6-icmp ip6 length 64 icmpv6 type echo-request icmpv6 code 0 icmpv6 parameter-problem 2497511425 icmpv6 taddr 0:0:618d:8d69::3b8b:a00
trace id a7268f01 inet fw4 oversea_mangle_output verdict continue meta mark 0x00000200
trace id a7268f01 inet fw4 oversea_mangle_output policy accept meta mark 0x00000200
trace id a7268f01 inet fw4 mangle_output packet: oif "pppoe-wan" ip6 saddr 2409:8a30:40a:b38c::A ip6 daddr 2400:3200::1 ip6 dscp cs0 ip6 ecn not-ect ip6 hoplimit 64 ip6 flowlabel 175028 ip6 nexthdr ipv6-icmp ip6 length 64 icmpv6 type echo-request icmpv6 code 0 icmpv6 parameter-problem 2497511425 icmpv6 taddr 0:0:618d:8d69::3b8b:a00
trace id a7268f01 inet fw4 mangle_output verdict continue meta mark 0x00000200
trace id a7268f01 inet fw4 mangle_output policy accept meta mark 0x00000200
trace id a7268f01 inet fw4 output packet: oif "pppoe-wan" ip6 saddr 2409:8a30:40a:b38c::A ip6 daddr 2400:3200::1 ip6 dscp cs0 ip6 ecn not-ect ip6 hoplimit 64 ip6 flowlabel 175028 ip6 nexthdr ipv6-icmp ip6 length 64 icmpv6 type echo-request icmpv6 code 0 icmpv6 parameter-problem 2497511425 icmpv6 taddr 0:0:618d:8d69::3b8b:a00
trace id a7268f01 inet fw4 output rule oifname { "eth10", "br-wan", "pppoe-wan", "pppoe-wan2" } jump output_wan comment "!fw4: Handle wan IPv4/IPv6 output traffic" (verdict jump output_wan)
trace id a7268f01 inet fw4 output_wan rule jump accept_to_wan (verdict jump accept_to_wan)
trace id a7268f01 inet fw4 accept_to_wan rule oifname { "eth10", "br-wan", "pppoe-wan", "pppoe-wan2" } counter packets 10658 bytes 1260866 accept comment "!fw4: accept wan IPv4/IPv6 traffic" (verdict accept)
trace id a7268f01 inet fw4 mangle_postrouting packet: oif "pppoe-wan" ip6 saddr 2409:8a30:40a:b38c::A ip6 daddr 2400:3200::1 ip6 dscp cs0 ip6 ecn not-ect ip6 hoplimit 64 ip6 flowlabel 175028 ip6 nexthdr ipv6-icmp ip6 length 64 icmpv6 type echo-request icmpv6 code 0 icmpv6 parameter-problem 2497511425 icmpv6 taddr 0:0:618d:8d69::3b8b:a00
trace id a7268f01 inet fw4 mangle_postrouting verdict continue meta mark 0x00000200
trace id a7268f01 inet fw4 mangle_postrouting policy accept meta mark 0x00000200
trace id a7268f01 inet fw4 srcnat packet: oif "pppoe-wan" ip6 saddr 2409:8a30:40a:b38c::A ip6 daddr 2400:3200::1 ip6 dscp cs0 ip6 ecn not-ect ip6 hoplimit 64 ip6 flowlabel 175028 ip6 nexthdr ipv6-icmp ip6 length 64 icmpv6 type echo-request icmpv6 code 0 icmpv6 parameter-problem 2497511425 icmpv6 taddr 0:0:618d:8d69::3b8b:a00
trace id a7268f01 inet fw4 srcnat rule oifname { "eth10", "br-wan", "pppoe-wan", "pppoe-wan2" } jump srcnat_wan comment "!fw4: Handle wan IPv4/IPv6 srcnat traffic" (verdict jump srcnat_wan)
trace id a7268f01 inet fw4 srcnat_wan verdict continue meta mark 0x00000200
trace id a7268f01 inet fw4 srcnat rule jump upnp_postrouting comment "Hook into miniupnpd postrouting chain" (verdict jump upnp_postrouting)
trace id a7268f01 inet fw4 upnp_postrouting verdict continue meta mark 0x00000200
trace id a7268f01 inet fw4 srcnat verdict continue meta mark 0x00000200
trace id a7268f01 inet fw4 srcnat policy accept meta mark 0x00000200
后来我想到测试一下 ipv4 是否能触发重路由,因为我之前研究双 wan 源入源出时,非常确定 TCP 是能够触发重路由的。没想到这次测试也没有触发重路由。好在我保留了之前测试时的 nft 脚本,对比发现不同的地方在于原本 nft 规则使用了 type route,而现在的是 type filter。这才想起来我这是我之前的临时修改,结果既没测试也没改回去。修正后问题便解决了,心里长舒一口气(我终于不用过年时修网络了)。
想起来 24 年过年时在修 wr30u 路由器,当时还学习尝试用焊枪去编程 WSON8 闪存,结果失败了,25 年使用 mtk_uartboot 工具通过串口修好了那个 wr30u,而这个 wr30u 则是在更早时买来用于 wifi6 网络升级组 mesh 的
nftable 和 iptable 对比¶
以下部分分析了为什么必须使用 type route,复习了 netfilter 的原理以及 nftables,iptables 的不同
重路由的原理¶
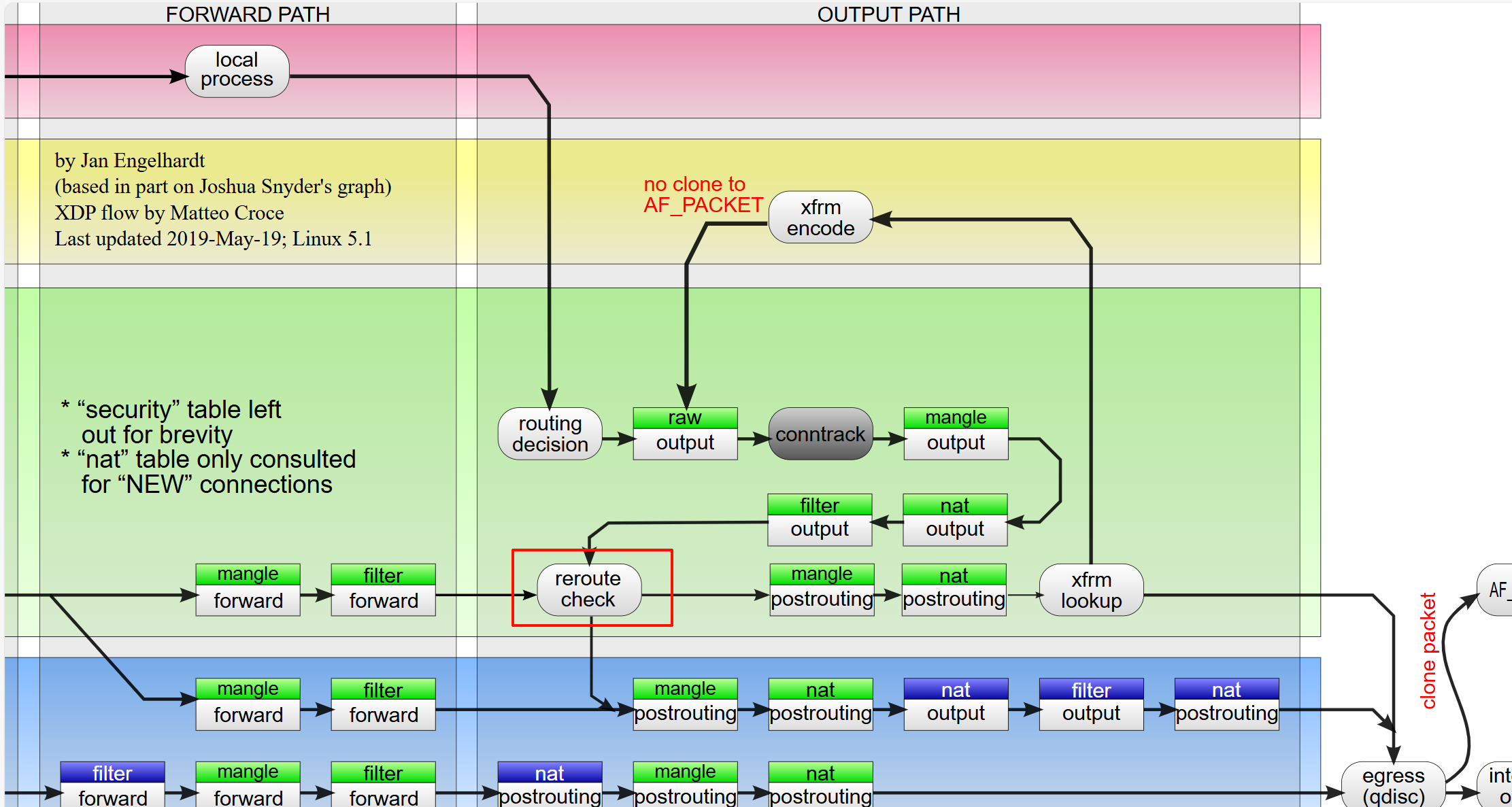
在 Linux 内核中,本地发出的数据包(Output)流程大致如下:
- 第一次路由查找:应用程序发送数据包,内核根据目的 IP 查找路由表,决定从哪个网卡发出,以及下一跳网关是谁
- 进入 Netfilter OUTPUT Hook:数据包进入
NF_INET_LOCAL_OUT挂载点。这里就是 nftwg_spoof_output链执行的地方 - 重新路由检查(Reroute Check):当数据包离开 OUTPUT Hook 后,内核会检查数据包的某些关键属性(如 Firewall Mark / fwmark、TOS 等)是否在 Hook 中被修改了
- 如果改变了:内核必须丢弃第一次的路由结果,根据新的 fwmark 重新进行路由查找(调用的函数类似
ip6_route_me_harder)。这对于策略路由(Policy Routing)至关重要 - 如果没改变:使用第一次的路由结果继续发送
- 如果改变了:内核必须丢弃第一次的路由结果,根据新的 fwmark 重新进行路由查找(调用的函数类似
- Postrouting:进入后续流程
在 prerouting 和 output 都有 reroute 检查,下图显示了 output 的 reroute 检查位置
更多 netfilter 知识参考
{kind=link}
nftables 的核心三要素:Type, Hook, Priority¶
- Hook (挂载点)
- 含义: “在哪里” 处理数据包
- 解释:这是内核代码中的具体位置。比如
prerouting(刚进网卡)、input(发给本机)、output(本机发出)、postrouting(即将离开网卡)。 - 作用:决定了数据包在生命周期的哪个阶段被你的规则捕获。
- Type (类型)
- 含义:“能做什么”
- 解释:它定义了这条链(Chain)背后的内核逻辑。
-
filter:标准类型。主要用于过滤(Accept/Drop)。它不期望数据包的路由属性被修改。 -route:重路由类型。专门用于 Output 阶段。如果在这种链里修改了 Mark,内核知道必须重新查路由表(Route lookup)。 -nat:地址转换类型。拥有连接跟踪(Conntrack)的特殊处理能力,通常用于 SNAT/DNAT。
- Priority (优先级)
- 含义:“先做还是后做”
- 解释:同一个 Hook 上可能挂着好几条链(比如一条做 NAT,一条做防火墙,一条做流量整形)。Priority 是一个数字,数字越小,越先执行。
- 助记:
-
priority filter其实等于数字 0。 -priority mangle其实等于数字 -150。 -priority nat其实等于数字 -100 (dstnat) 或 100 (srcnat)。 - 作用:决定了如果我有两条链都在
hook output,谁先拿到数据包。
iptable 和 nftable 不同,它的 type 被硬编码在“表(Table)”的名字上了:
- 当你使用
iptables -t filter表时 -> 内核自动创建类似 nft 的type filter链。 - 当你使用
iptables -t mangle表时 -> 内核自动创建类似 nft 的type route链(特别是在 Output 链上)。 - 当你使用
iptables -t nat表时 -> 内核自动创建类似 nft 的type nat链。
nftables 解耦了“表名”和“功能”。你可以创建一个叫 my_table 的表,然后在里面混合放 NAT 链、Filter 链和 Route 链。这是 iptables 做不到的。
使用 iptable 实现一样的功能¶
- 必须用
mangle表(因为只有 mangle 表的 OUTPUT 链具备重路由检测能力,即对应 nft 的type route) - iptables 没有直接的
numgen(数字生成器)和map映射功能,需要用statistic模块来实现轮询(Round Robin)
# 第一条规则:匹配 50% 的包(每 2 个包里的第 1 个),打上 0x100
ip6tables -t mangle -A OUTPUT -p udp -m statistic --mode nth --every 2 --packet 0 -j MARK --set-mark 0x100
# 第二条规则:匹配剩下的包(每 2 个包里的第 2 个),打上 0x200
ip6tables -t mangle -A OUTPUT -p udp -m statistic --mode nth --every 2 --packet 1 -j MARK --set-mark 0x200
sunshine 配置¶
iperf3 测速时可以观察到 8000 Retr 次数,是有一定的丢包的。因此推荐增大 sunshine 的 FEC 参数。
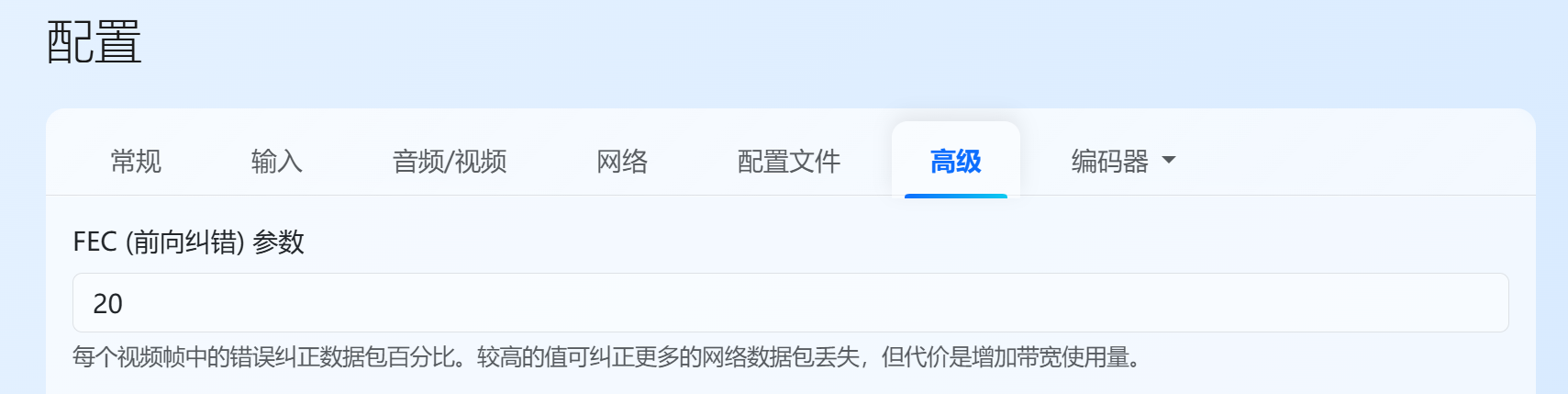
FEC 设置成 30,4K 串流测试时没有观察到丢帧。bmon 可以看到两个 wan 口上的流量对比。
SQM 优化¶
在问 gemini BBR 能否优化 moonlight 串流时,gemini 给我提供了以下优化方法:
1 调整 WireGuard 的 MTU (最关键!)
异地组网串流最大的杀手是 IP 分片。
- 现象:视频流是大数据包,WireGuard 加密会增加包头。如果 WireGuard 的 MTU 设置太大(默认 1420),加上 PPPoE 的开销,数据包极其容易超过运营商的限制(通常 1492 或 1480),导致包被切碎(分片)。
- 后果:UDP 只要有一个分片丢了,整个视频帧就废了,导致画面瞬间马赛克或卡顿。
- 操作:
在你的 N4500 (旁路由) 和 异地 WireGuard 节点 上,把 WireGuard 接口的 MTU 改小。- 建议值:1280(这是 IPv6 的最小标准值,也是最稳的值)。
- 虽然 1280 会稍微降低一点传输效率(约 1-2%),但能彻底避免分片,对串流流畅度提升巨大。
2 开启 SQM (Smart Queue Management)
虽然 BBR 不管 UDP,但 OpenWrt 里的 SQM (Cake/FQ_Codel) 管!
- 原理:SQM 能够智能识别小包(手柄操作、游戏指令)和大包(视频流),防止视频流把手柄操作堵在后面(导致输入延迟),同时能平滑视频流的突发数据。
- 操作:
1. 在 N4500 的 ImmortalWrt 里安装
luci-app-sqm。 2. 在“网络” -> “SQM QoS”里启用。 3. 接口:选择你的 WireGuard 接口(或者负责上传的 WAN 口)。 4. 队列规程 (Queuing Discipline):选择 Cake 或者 fq_codel。 5. 上传/下载速度:设置为你实际带宽的 90-95%。
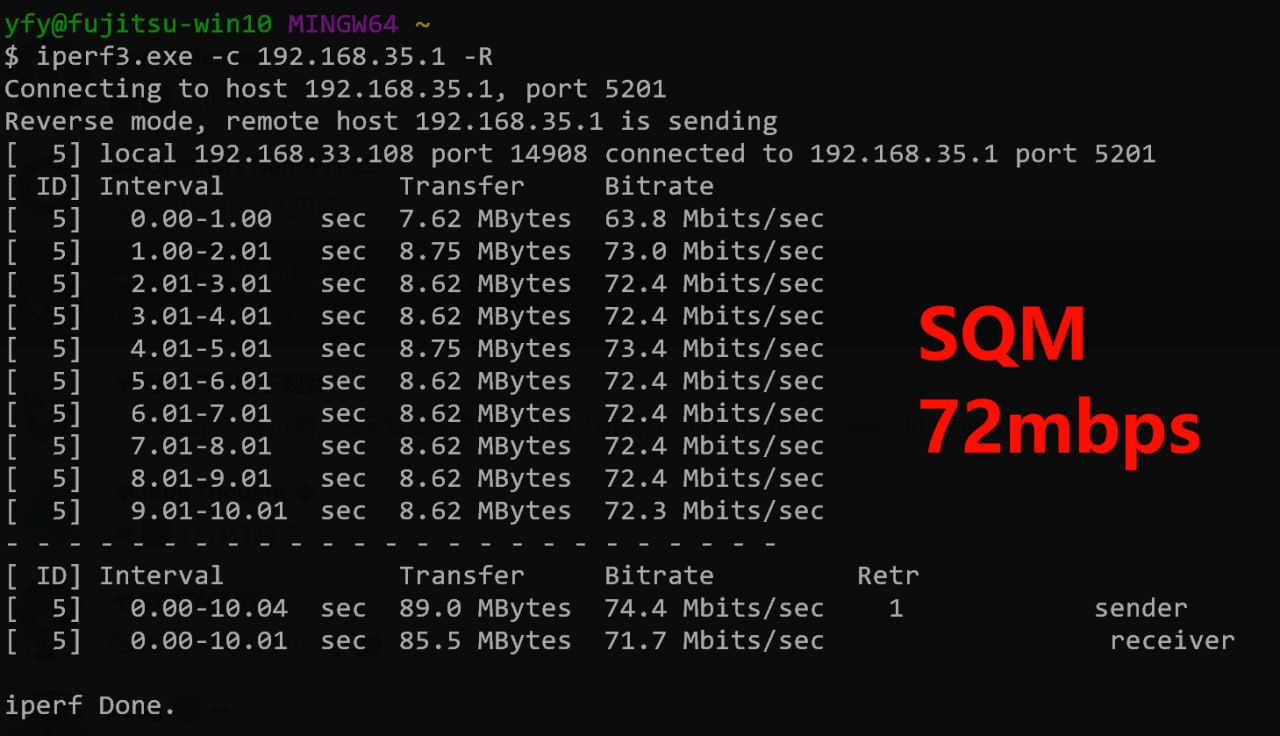
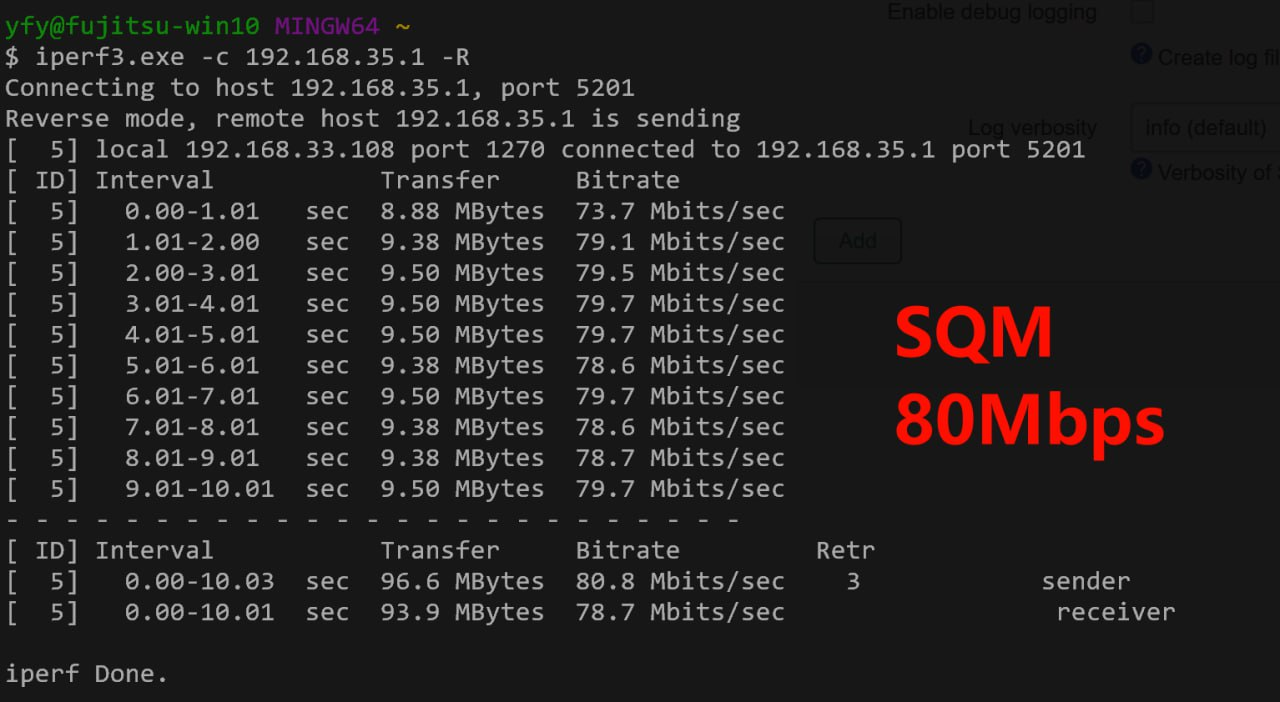
在尝试设置 SQM 后,效果居然非常显著。iperf3 测速 Retr 丢包直接变为个位数,并且带宽完全遵从 SQM 里设置的最大值,最大可以跑到接近 80Mbps。
其它优化¶
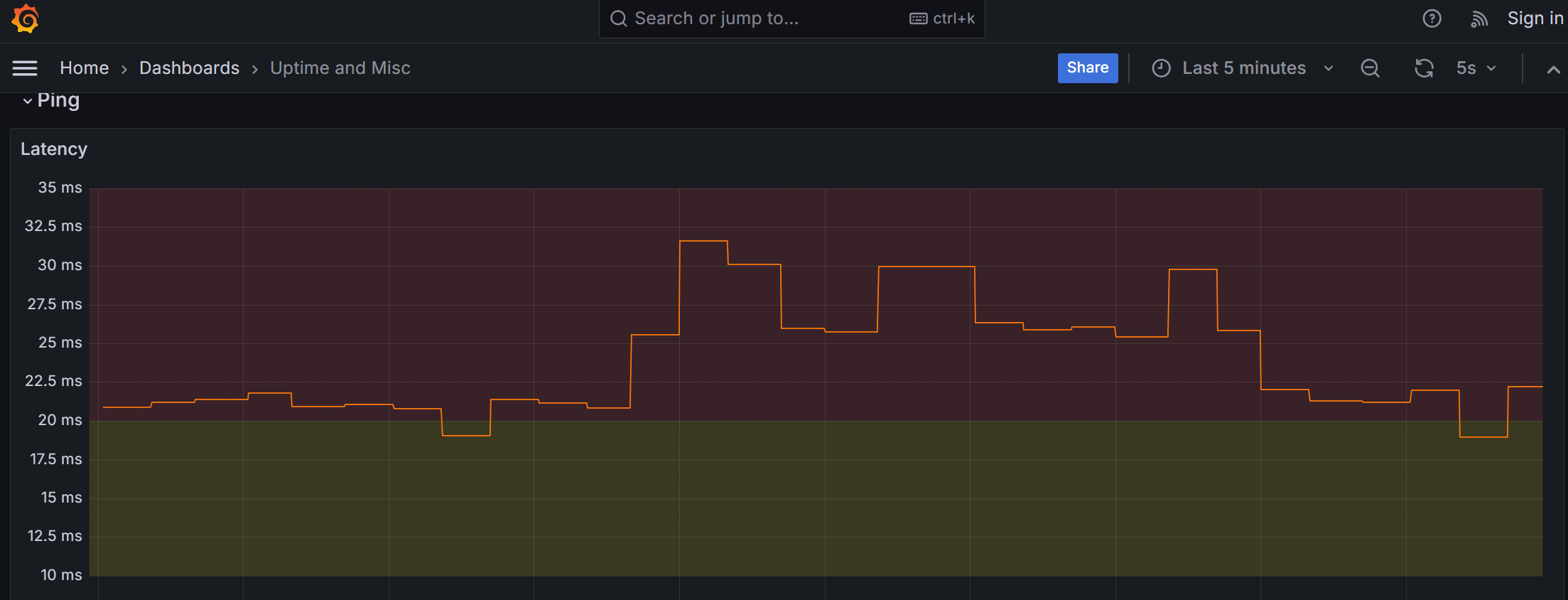
wireguard 组网时,通过反复启动和停止 wg 接口,让 wg 随机使用不同端口,可以影响运营商的路由,降低隧道延迟。
这是我反复抽奖时网络延迟记录。我刚开始抽到的 20ms 已经是最低的延迟了,我再重新抽奖时,只能抽到 > 25ms 以上的端口(对应中间那段凸起),于是我又把端口改回去了。
结语¶
这次过年期间,我终于在家宽上实现了我心心念念的 4K 串流。我用它来愉快地玩耍了很久燕云十六声,操作起来很顺手。另外,令我感到惊喜的是,去年给家里换的电视(小米 S Pro Mini LED)居然还有 HDR 功能,并且参数很不错(1792 分区,3000-4000nit,95% DCI-P3)。我用它试了下剑星的 HDR 模式,和我买的以 HDR 效果著称的 VA 屏的雷鸟 U8 显示器对比,没有看出区别,天空也是又白又亮,没有光晕很干净(除了颜色可能要调节一下)
再加上我可以白嫖部门老大放置在公司的,一台闲置的 4090 显卡机器(我回来前也把网络、串流都搞定了,有 200Mbps 的上传),又有不一样的玩法。N 卡 40 系支持 VSR 功能,可以将浏览器画面超分到 4K。并且最重要的是,它还有一个容易被忽略的功能——它支持将 SDR 内容转换成 HDR 内容。我测试了 VSR 的 HDR 效果很不错,一些视频的观感有很大提升(HDR 此时比 1080p 到 4K 的提升还要大)。使用这套组合拳,我可以舒舒服服地在大电视刷 B 站时享受 4K HDR 的内容了。
那么问题来了,下一次,我的网络/串流要优化什么呢?